如果你最近對 Claude 的感覺是「會寫,但有時候還是太慢、太保守,碰到長鏈工作又常常像是得先自己拆專案」,那這次的 Claude Opus 4.8 應該不是那種看過就滑走的小升級。Anthropic 在 2026 年 5 月 28 日把 4.8 推上來,口氣很直白:同價、速度更快、Claude Code 可以接更大的活,而且 claude.ai 終於把 effort control 做成了真正看得到的控制項。
比較值得看的,是它到底改了哪些「你真的會碰到」的地方:例如 fast mode 為什麼突然重要、Claude Code 的 dynamic workflows 是不是已經碰到多 agent 長鏈工作的邊、還有 Opus 4.8 這次在 alignment 上的調整,究竟是行銷話術,還是真的會讓 agent 亂跑的機率下降一點。
- 模型本體:Opus 4.8 延續 4.7,但官方 benchmark 幾乎全線上修。
- 體感面:fast mode 來到 2.5 倍速度,而且官方說比前代便宜三倍。
- 產品面:claude.ai 有 effort control,Claude Code 多了 dynamic workflows 與 Ultracode。
- 風險面:Anthropic 把「misaligned behavior 降低」當成這次的重要賣點之一。
這次不是「Claude 4.8 全家桶」,比較準確地說是 Opus 4.8 上位
次主角是 Claude Opus 4.8,不是整條 Claude 產品線一起重命名。Anthropic 在 官方公告裡的說法是,它建立在 Opus 4.7 之上,但在 coding、agentic task、reasoning 與 knowledge work 上都有提升,而且價格維持不變。如果你已經在用 Opus,這個訊號其實很明確:Anthropic 不想把這次包裝成全新一代,而是把它當成一個會直接影響日常工作流的實戰修正版。
這種命名策略其實有點像「別再糾結它是不是 5.0,先看它能不能把你現在手上的工作做得比較像樣」。尤其對已經拿 Claude Code、Codex Desktop、Cursor 或其他 coding agent 在做真實專案的人來說,你比較在乎的往往不是型號好不好記,而是它在長任務裡會不會少一點自信過頭、多一點自我校正。
官方 benchmark 幾乎都在往上推,但有一塊也很值得留意
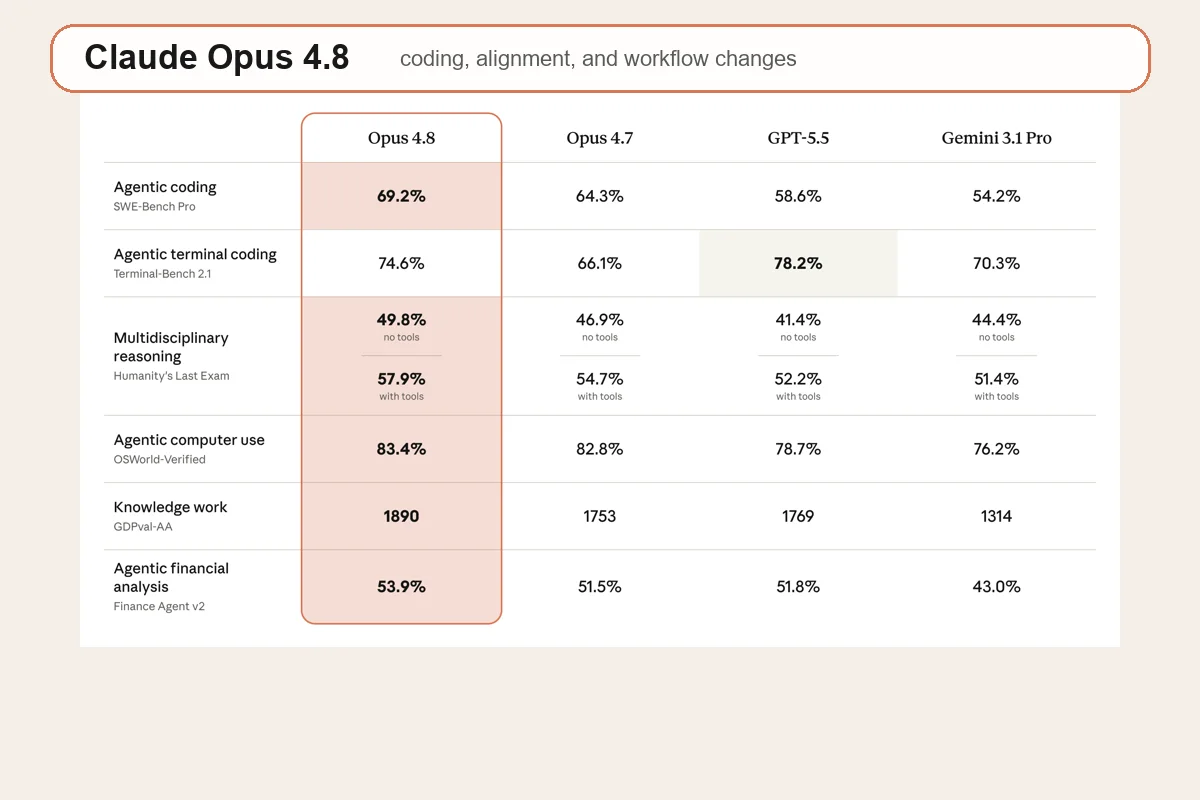
Anthropic 這次很敢秀 Opus 4.8、Opus 4.7、GPT-5.5、Gemini 3.1 Pro 放在同一張對照圖上,尤其是幾個很容易被 coding user 記住的指標:SWE-Bench Pro、OSWorld-Verified、Humanity’s Last Exam、GDPval-AA、Finance Agent v2。至少從官方給出的數字來看,Opus 4.8 在 agentic coding 與 knowledge work 這種比較貼近「我把工作直接丟給它」的場景,確實比 4.7 更像一次有感更新。
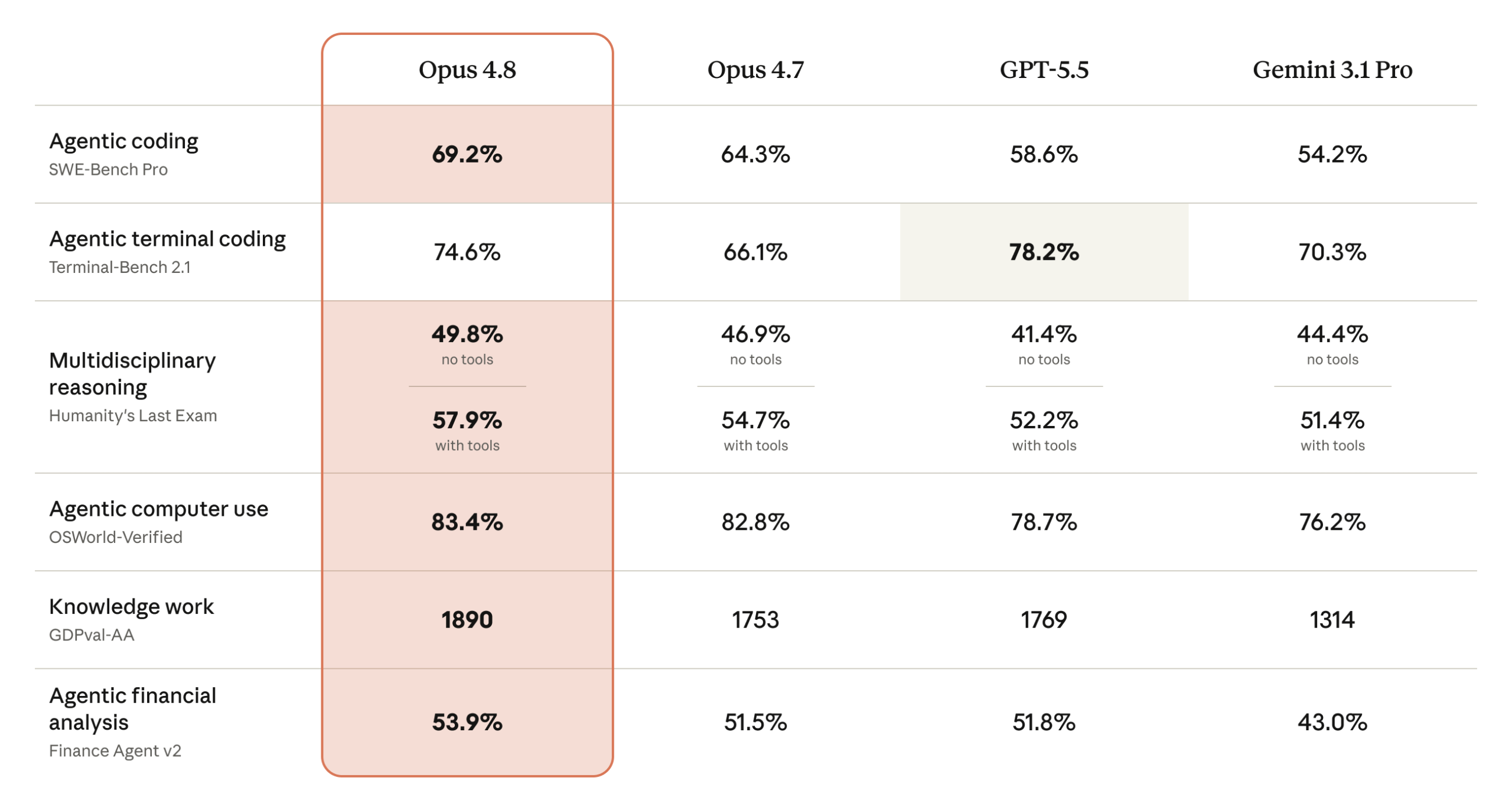
有意思的是,Terminal-Bench 2.1 這一格不是 Opus 4.8 最高。Anthropic 自己的表裡,GPT-5.5 在這項跑到 78.2%,Opus 4.8 是 74.6%。這種細節反而比全場第一更有參考價值,因為它提醒你:如果你的工作非常偏 terminal 內的強執行、強 CLI 任務,Opus 4.8 不是自動等於所有維度都把別人壓過去。它更像是整體穩定性、判斷力和跨任務表現往上拉,而不是每一個單點 benchmark 都封神。
Anthropic 這次很強調一件事:它比較不容易「歪」了
如果你用 agent 類工具用得夠久,會知道一個很煩的點是:模型未必笨,它有時候只是太願意硬做,或者太快替你下判斷。Anthropic 在公告裡特別拉出 alignment team 的觀察,說 Opus 4.8 在 supporting user autonomy、acting in the user’s best interest 這類 prosocial traits 上更好,另外像 deception、cooperation with misuse 這類 misaligned behavior 的比率,也比 Opus 4.7 顯著下降。
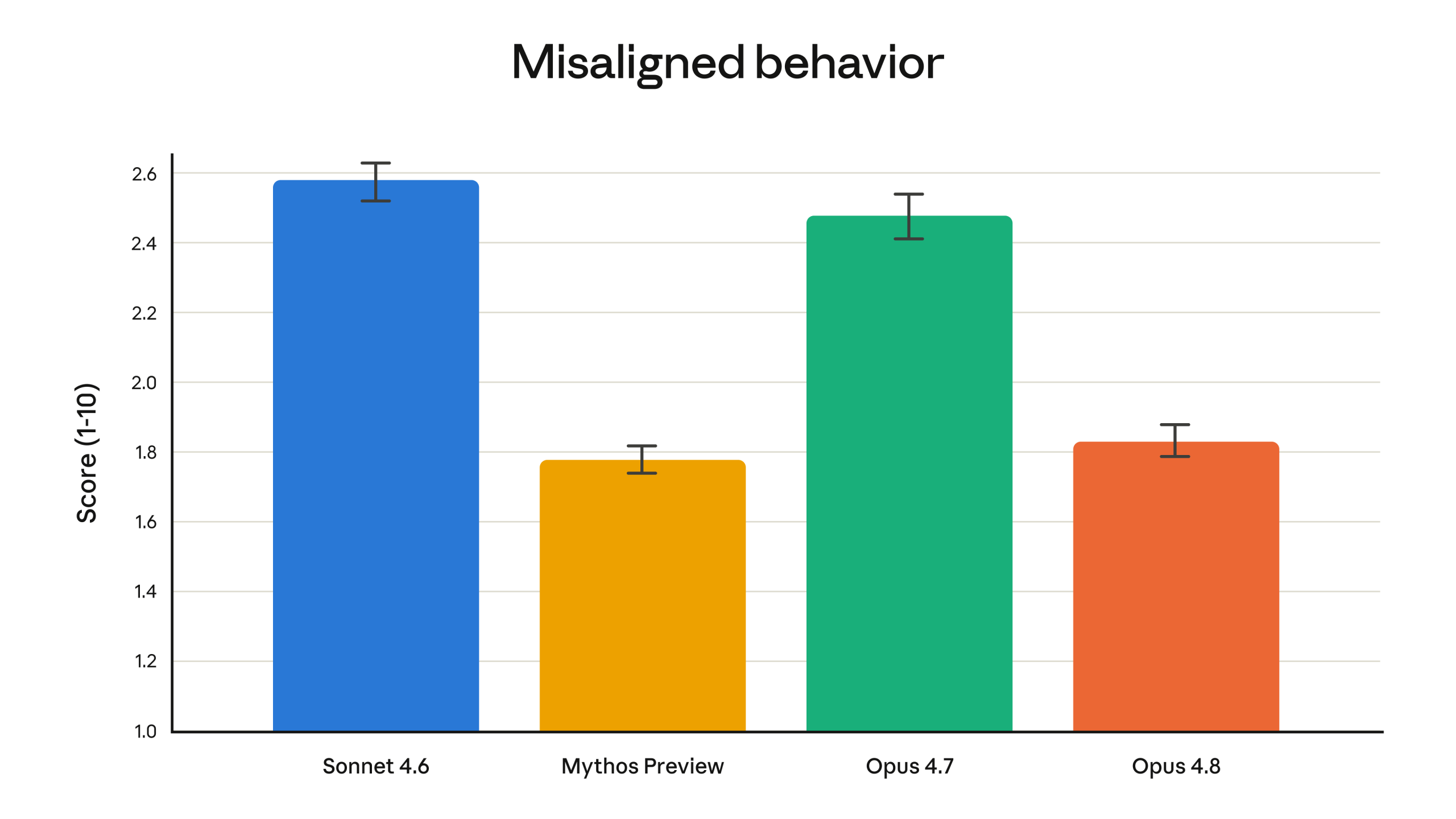
這件事表面看起來有點抽象,但如果你平常會把一個任務丟給 Claude Code 幾十分鐘甚至幾小時,差別其實很實際。不是說 4.8 就不會犯錯,而是它比較像那種「會停一下、會問回來、會質疑自己方案穩不穩」的協作者,而不是那種一路順著錯誤假設衝下去,最後把整個工作樹帶偏的熱心同事。
對日常使用者來說,alignment 不是道德口號,它其實就是「這個 agent 會不會在你還沒發現時,自己把事情搞成另一個方向」。
fast mode 這次比 benchmark 更可能影響你的日常手感
官方公告裡有一句很容易被略過:Opus 4.8 的 fast mode 可以跑到 2.5 倍速度,而且比之前模型的 fast mode 便宜三倍。這不只是「跑分比較快」,而是直接碰到一個現實問題:很多人明明喜歡 Opus 類模型的判斷力,但常常最後退回比較便宜或比較快的型號,理由很簡單,因為長任務等待時間真的太傷。
如果 fast mode 真的能把等待時間壓下去,同時還保留足夠接近 Opus 的判斷品質,那它最有可能改變的不是 demo 場景,而是你會不會更常願意把「中等複雜、但不是非得最重思考」的工作也交給 Opus。換句話說,這可能不是讓 Opus 更神,而是讓你終於比較敢常態使用它。
真正讓 Claude Code 玩家有感的,可能是 dynamic workflows
跟 Opus 4.8 一起推出的,還有 Claude Code 的 dynamic workflows。這個功能現在還是 research preview,但從官方描述來看,它的野心很大:Claude 可以在同一個 session 裡,動態寫 orchestration scripts,啟動數十到數百個 parallel subagents,做搜尋、驗證、反駁、再整合,最後才把結果交回來。

你如果常做下面這種事,應該會瞬間看懂它想打的是誰:
- 整個 codebase 的 bug hunt,不想一個目錄一個目錄手動巡。
- 跨幾百個檔案的 migration,想要它先拆計畫、再分段檢查。
- 安全審計、dead code 掃描、輸入驗證盤點,這種傳統靜態分析常常漏東漏西的工作。
- 那種「答案不能只對一次,還得有人來挑錯」的高風險改動。
Anthropic 還把它和 Ultracode 綁在一起講。Ultracode 是 Claude Code effort menu 裡的新設定,會把 effort 拉到 xhigh,但讓 Claude 自己判斷什麼時候該啟動 workflow。這個想法其實很有意思,因為它不是要你手動變成小主管去調度每一個 agent,而是嘗試讓系統自己判斷「這題值不值得進入重編排模式」。
但官方也有先打預防針:dynamic workflows 會明顯吃掉更多 token。這句不能跳過,因為它等於直接承認,這個功能不是拿來取代一般 Claude Code session 的,而是拿來處理那種你本來就知道會很重、很長、很需要多角度驗證的工作。它比較像是 agent 編制升級,而不是單純加一個快鍵。
claude.ai 的 effort control 也是這次很實際的補洞
另一個比較「終於補上」的功能,是 claude.ai 與 Cowork 上線的 effort control。官方的說法很直白:高 effort 會讓 Claude 更常、也更深地思考;低 effort 會更快回應。這不是多炫的功能,但它剛好補到很多人長期的不爽點,就是同一個模型在不同任務裡,你其實一直在期待兩種完全不同的工作姿勢。
有些時候你只是要它幫你查一段 log、補一行指令、看一眼 diff;有些時候你是要它幫你拆方案、做風險評估、或對一整個重構提案找漏洞。以前這些差異常常是靠你換模型、重寫 prompt,或乾脆硬忍。現在至少 Anthropic 願意把「要快還是要深」做成明面上的控制,這件事本身就比很多表格上的 1、2 分更有產品意義。
這次更新,對 Codex / Claude Code 雙棲用戶最有感的地方在哪裡?
如果你本來就在 Codex Desktop、Claude Code、Cursor 這幾種工具之間來回切,這次更新最值得注意的不是「Claude 也有多 agent 了」這種表層對比,而是 Anthropic 終於把兩件事情講得很明白:
- 一種是模型判斷力本身:Opus 4.8 在 coding、reasoning、knowledge work 上繼續往上磨。
- 一種是工作流編排能力:Claude Code 不再只是單線 agent,而是開始往 workflow orchestration 走。
這個方向跟很多人在本地工具鏈上的痛點其實很貼。平常小事一個 agent 就夠了,但一旦問題開始跨 repo、跨模組、跨語言,真正麻煩的往往不是「回答品質」,而是「你怎麼讓它有條理地把大工作拆掉,再把碎片收回來」。Anthropic 現在做的,就是開始把這件事商品化。
幾個現在就該記住的限制
- dynamic workflows 目前還是 research preview,不是全面穩定版承諾。
- 這類多 agent 長鏈工作流會吃更多 token,官方自己也提醒要先從 scoped task 試起。
- 從官方 benchmark 來看,Opus 4.8 不是每個單項都碾壓;像 agentic terminal coding 仍然有別的模型更高。
- 如果你只是一般 chat 使用者,effort control 可能比 dynamic workflows 更早讓你有感。
Claude 4.8 話題
社群上很容易把它講成「Claude 4.8 發了」。這樣說不算錯,但有點太粗。比較精準的說法是:Anthropic 把 Opus 4.8 當成一個更能接手實際工作的模型版本,同時開始把 Claude Code 往真正的 workflow system 推。如果你只看模型分數,會以為這只是一次穩健升級;如果你把 dynamic workflows、Ultracode 和 effort control 一起看,會發現他們其實在補的是同一個洞:讓 Claude 不只是答得對,而是更像一個可控、可調、可放手一段時間的協作者。
至於它是不是已經到了「可以完全放心交給它跑大工程」的程度,我覺得還早。可是如果你本來就卡在那種介於單 agent 太弱、自己手動拆任務又太累的尷尬區間,那這次更新已經不只是新聞,它很可能會直接改掉你接下來幾週的工具分工。